이 연구는 고성능 분할 모델인 SAM을 teacher로 활용하면서도, 경량 student 구조를 설계하여 이상 탐지의 정확도, 속도, 메모리 효율성 모두를 균형 있게 확보한 우수한 접근으로 평가된다.
제안된 모델은 MVTec AD, VisA, DAGM, LOCO와 같은 다양한 산업용 비지도 이상 탐지 벤치마크에서 우수한 성능을 보였다. 따라서 고정된 카메라 기반의 공정 검사, 제조 현장의 표면 결함 감지, 실시간 불량 판별 등에서 효과적으로 활용될 수 있다.
또한 모델이 SAM의 일반화 능력을 기반으로 설계되었고 경량화되어 있어, 모바일 기기, 로봇 비전 시스템, IoT 엣지 디바이스 등 자원이 제한된 환경에서도 실시간 이상 탐지에 유리할 것으로 보인다.
1. 문제 배경
- 이미지 이상 탐지(Anomaly Detection, AD)와 이상 위치 지정(Localization)은 산업용 품질 검사, 의료 영상 분석, 영상 감시 등의 다양한 분야에서 활용된다.
- 그러나 이상(anomaly)은 매우 드물게 발생하고, 그 형태도 다양하기 때문에 모든 이상 패턴을 포함한 학습 데이터셋을 구축하는 것은 어렵다.
- 이에 따라 대부분의 연구는 비지도 학습 기반 접근법을 사용하며, 정상 샘플만으로 모델을 학습시킨다
기존 방법의 한계
- 재구성 기반 방법:
- 오토인코더(AE), 변분 오토인코더(VAE), GAN 등을 활용해 정상 이미지를 복원하도록 학습한다.
- 테스트 시 복원 오차를 통해 이상 여부를 판단하지만, 최근 연구에 따르면 모델이 이상 영역까지 잘 복원하는 경우가 있어 탐지 정확도가 저하된다.
- 메모리 뱅크 기반 방법:
- 훈련된 백본에서 추출한 특징을 저장하고, 테스트 샘플과의 유사도를 계산하여 이상을 탐지한다.
- 그러나 계산 복잡도와 메모리 사용량이 크다.
- 지식 증류(Knowledge Distillation, KD) 기반 방법:
- 정답을 제공하는 대형 teacher 모델의 지식을 경량 student 모델에 전달하여 학습한다.
- 정상 이미지에 대해서만 학습한 student는 이상 이미지에서 teacher와 차이가 발생하므로 이를 통해 이상을 탐지한다.
- 하지만 teacher와 student가 구조적으로 유사하면 성능이 떨어지는 문제가 있다.
새로운 접근 필요성
- 최근 등장한 Segment Anything Model(SAM)은 대규모 학습을 통해 보지 못한 이미지에 대해서도 뛰어난 분할 결과를 보여주는 foundation model이다.
- 하지만 SAM은 약 615M개의 파라미터를 가지며, 실시간 또는 모바일 환경에서 사용하기에는 부적합하다.
제안 방식(STLM)의 핵심 개념
- 본 논문에서는 SAM의 일반화 능력을 활용하면서도 경량화된 모델 구조를 목표로 한다.
- 이를 위해 SAM에서 지식을 증류받는 두 개의 스트림(plain stream, denoising stream)을 포함한 STLM(SAM-guided Two-stream Lightweight Model)을 제안한다.
- Plain stream은 이상이 있는 이미지로부터 일반화된 특징 표현을 학습한다.
- Denoising stream은 인위적인 이상이 삽입된 이미지를 입력으로 받아 원래의 정상 이미지를 복원하도록 학습한다.
- 두 스트림의 출력 차이를 활용해 이상 영역을 효과적으로 구분하며, 이후 마스크 디코더와 Feature Aggregation 모듈을 통해 이상 맵을 생성한다.
성능 및 기여
- 제안 모델은 약 16M의 파라미터만 사용하며, 추론 시간은 약 20ms 수준이다.
- MVTec AD 기준 픽셀 단위 AUC 98.26%, PRO 94.92%의 성능을 달성하였으며, VisA 및 DAGM 등 복잡한 데이터셋에서도 우수한 결과를 보였다.
- 제안 방식은 경량성, 높은 정확도, 실시간 처리 능력을 모두 충족하는 새로운 이상 탐지 모델을 제시하였다.
2. Related Work
본 논문의 관련 연구는 크게 세 가지 범주로 나눌 수 있다.
1. Deep Learning Methods for Anomaly Detection and Localization
- 재구성 기반 방법:
- 오토인코더(AE), 변분 오토인코더(VAE), GAN 등을 사용하여 정상 이미지를 복원하고, 복원 오류를 기반으로 이상을 탐지한다.
- 하지만 복잡한 패턴이나 텍스처를 갖는 이미지에 대해서는 이상 영역까지 복원되는 경우가 있어 성능에 한계가 있다.
- 메모리 뱅크 기반 방법:
- 사전 학습된 백본에서 특징을 추출한 후, 정상 샘플의 특징을 메모리 뱅크에 저장하고 새로운 샘플과의 패치 단위 거리 비교를 통해 이상 여부를 판단한다.
- 계산 복잡도와 메모리 요구량이 높다는 단점이 있다.
- 지식 증류(Knowledge Distillation, KD) 기반 방법:
- teacher와 student 네트워크 간의 표현 차이를 이용해 이상을 탐지한다.
- 대표적으로 multi-resolution KD나 denoising student를 활용한 방식이 존재한다.
- 그러나 teacher가 보지 못한 정상 패턴을 잘 표현하지 못하거나, student가 이상에 대해 충분히 일반화되지 못하는 문제가 존재한다.
2. Vision Foundation Models
- 대형 사전 학습 모델(예: GPT 시리즈, CLIP, DINO, SAM)은 학습된 지식을 바탕으로 다양한 다운스트림 작업에 강한 일반화 능력을 보인다.
- CLIP:
- 이미지-텍스트 쌍으로 학습되어 장면 수준의 의미는 잘 포착하지만, 객체 수준 또는 이상 탐지에는 한계가 있음.
- DINO:
- 비지도 학습 기반으로 강력한 특징 표현을 학습하며, 최근 DINOv2에서는 패치 수준 재구성 기능까지 강화됨.
- SAM:
- 수백만 개의 주석 이미지로 학습되어 고품질 분할 결과를 제공하며, 보지 못한 이미지에 대해서도 제로샷 분할이 가능함.
- 단점:
- 대부분 Transformer 기반이라 연산량이 크고, 의료 영상이나 이상 탐지 등 특수한 도메인에는 일반화 성능이 낮을 수 있음.
3. Lightweight Models
- 경량화 모델은 제한된 자원을 가지는 환경(모바일, 로봇 등)에 적합하게 설계된 모델로서, 다음과 같은 접근이 있다.
- 모델 프루닝, 양자화, KD 등을 통해 경량화
- MobileNet, ShuffleNet, CSPNeXt 등 CNN 기반 경량 구조
- 그러나 이상 탐지와 같은 비지도 학습 상황에서는 정확도와 일반화 성능을 유지하면서 경량화를 달성하는 것이 여전히 도전적이다.
- Transformer 기반 모델은 전역 정보를 잘 포착해 해석 가능성이 높지만 연산량이 많다.
- 최근에는 ViT 기반의 경량 구조나 Transformer 최적화도 진행 중이다.
3. Method

본 논문은 SAM(Segment Anything Model)의 일반화 능력을 활용하면서도, 경량화된 구조로 실시간 이상 탐지가 가능한 STLM (SAM-guided Two-stream Lightweight Model)을 제안한다. 전체 프레임워크는 다음과 같은 네 가지 구성 요소로 이루어진다.
1. Pseudo Anomaly Generation (가짜 이상 생성)
STLM은 정상 이미지에 인위적인 이상을 삽입해 학습 데이터 다양성을 확보하며, 이를 통해 모델의 일반화 성능을 높인다.
Pseudo anomaly는 다음과 같이 생성된다:

| N | 정상 이미지 (normal sample) |
| A | 외부에서 가져온 임의의 이미지 (arbitrary image) — 이상 소스로 활용됨 |
| M | 이상 영역을 지정하는 바이너리 마스크 (Perlin noise → binarization) |
| M~ | 마스크의 보수 (즉, M~ = 1 - M) |
| ⊙ | 원소별 곱 (element-wise multiplication) |
| β | 불투명도 제어 파라미터 (opacity parameter) — [0, 1] 범위 |
단계별 해석
- M~⊙
- 마스크가 0인 부분 → 정상 이미지 N 그대로 유지
- 즉, 비이상 영역은 그대로 정상 이미지로 구성
- M⊙
- 마스크가 1인 부분 → 외부 이미지 의 픽셀 값을 삽입
- 완전한 이상으로 간주되는 영역
- M⊙
- 마스크가 1인 부분 → 정상 이미지 NN의 값도 일부 유지
- 이와 M⊙를 적절히 혼합함으로써 완전히 이상적이지도 않고, 완전히 정상이 아닌 중간적 영역을 생성
- 혼합 제어 (1 - β), β
- 일 경우: 외부 이미지와 정상 이미지의 혼합 정도를 절반씩 설정
- β가 클수록 정상 이미지 쪽을 더 많이 반영 → 이상이 더 미묘해짐
즉, 마스크가 0인 영역은 정상 이미지를 그대로 사용하고, 마스크가 1인 영역은 외부 이미지와 정상 이미지의 혼합으로 대체되어 이상처럼 보이도록 한다. 이 방법은 학습 시 실시간으로 적용되며, 50% 확률로 활성화된다.
2. Two-stream Lightweight Model (TLM)
SAM을 teacher로 활용하고, 두 개의 student stream으로 구성된 경량화 네트워크이다.
(1) Plain Student Stream
- 이상이 포함된 이미지를 입력으로 받아 분별력 있고 일반화된 특징 표현을 학습한다.
- SAM의 특징 지도를 참조하며 학습하되, 그대로 복제하지 않고 더 간결하고 표현력 있는 특징을 생성한다.
(2) Denoising Student Stream
- 가짜 이상이 삽입된 이미지를 입력으로 받아 정상 이미지의 특징을 복원하도록 학습한다.
- SAM이 원본 정상 이미지로부터 생성한 특징과의 코사인 유사도를 최소화하는 방식으로 학습한다.
Knowledge Distillation (KD) 손실
- 두 stream은 SAM에서 추출한 특징과의 코사인 거리 기반 손실로 학습된다:
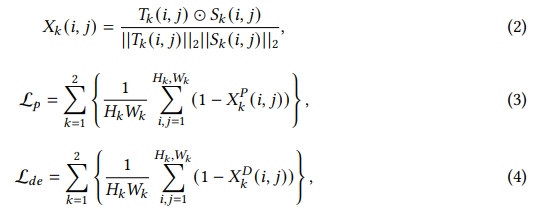
- 수식 (2): 코사인 유사도 기반 유사도 맵
- 각 위치에서 teacher와 student 특징의 방향 유사도(정규화된 내적)를 측정하며, 1에 가까울수록 유사한 특징을 갖는다는 의미한다
- 수식 (3): Plain Student 손실
- plain stream이 teacher의 특징을 모방하도록 유도하는 역할을 하며, 코사인 유사도가 1에 가까울수록 손실이 작아진다.
- 수식 (4): Denoising Student 손실
- denoising stream이 이상이 삽입된 이미지로부터 정상적인 특징을 복원하도록 학습하는 데 사용된다.
3. Feature Aggregation (FA) Module
- 두 stream의 특징 간의 차이를 효과적으로 통합하여 이상 맵(anomaly map)을 생성한다.
- 구성: 두 개의 residual block + ASPP (Atrous Spatial Pyramid Pooling)
- 입력: plain stream과 denoising stream의 feature 간 element-wise product
- 출력: 픽셀 단위의 이상 확률 맵
손실 함수

- 수식 (5): 픽셀 단위 예측값
- 모델의 예측값이 SAM의 정답 마스크와 얼마나 일치하는지 픽셀 단위로 계산
- 수식 (6): Focal Loss
- 예측이 틀린 픽셀에 더 큰 가중치를 두는 방식으로 학습하는 손실 함수.
- 수식 (7): L1 Loss
- 예측 마스크와 정답 마스크 간의 평균 절대 오차를 최소화하는 손실 함수.
4. Training & Inference
Training
- 전체 손실:

- 1-Stage 학습 방식 사용: TLM과 FA를 동시에 학습하며 성능이 더 우수함
Inference
- 추론 시 SAM은 사용되지 않고, 학습된 TLM과 FA 모듈만 사용되어 실시간 처리 가능
- 이미지 단위 이상 점수는 이상 확률 맵의 상위 k개 픽셀 평균으로 계산됨
구성 요소 역할
| Pseudo anomaly | 정상 이미지에 인위적 이상 생성하여 학습 다양성 확보 |
| Plain Stream | 일반화된 특징 표현 학습 (이상 포함) |
| Denoising Stream | 이상 이미지를 복원하여 정상 패턴을 학습 |
| FA Module | 두 stream의 특징 차이를 바탕으로 이상 맵 생성 |
4. Experiments
본 실험은 제안된 STLM(SAM-guided Two-stream Lightweight Model)의 성능을 기존 SOTA 방법들과 비교하여 정량적, 정성적, 그리고 분석적으로 평가한다. 다양한 데이터셋과 지표를 통해 정확도, 속도, 모델 크기, 일반화 능력을 검증하였다.
4.1. 데이터셋

| MVTec AD | 15개 클래스 (10개 객체 + 5개 텍스처), 이상 탐지 및 위치 지정용 벤치마크 |
| VisA | 12개 객체, 3개 도메인 포함, 대규모 산업용 이상 탐지 데이터셋 (총 10,821장) |
| MVTec LOCO | 구조적 + 논리적 이상 포함 (본 논문에서는 구조적 이상만 사용) |
| DAGM | 텍스처 기반, 배경과 유사한 미세 이상이 존재하는 데이터셋 (총 10개 클래스) |
4.2. 평가 지표
| Image-level AUROC (I) | 전체 이미지 단위의 이상 판단 정확도 |
| Pixel-level AUROC (P) | 픽셀 단위의 이상 탐지 정확도 |
| PRO (Per Region Overlap) | 이상 영역의 실제 위치와 예측 간의 겹침 정도 |
| AP (Average Precision) | 픽셀 기반 정확도. imbalance 상황에 강함 |
4.3. 구현 세부사항
- Encoder: ViT-Tiny (MobileSAM 기반)
- 최적화:
- TLM: Adam (lr=0.0005)
- FA 모듈: SGD
- 이미지 해상도: 1024×1024
- Epoch: 200, Batch size: 2
- 추론 스코어 계산: 이상 점수 맵에서 상위 100개 픽셀 평균
4.4. 평가 결과
MVTec AD 성능 비교
- STLM 평균 성능:
- Image-level AUROC: 99.05%
- Pixel-level AUROC: 98.26%
- PRO: 94.92%
- Inference time: 20ms (2번째로 빠름)
- Parameters: 16.56M (최소)


다양한 벤치마크 결과
STLM은 특히 PRO, AP에서 모든 데이터셋에서 우수한 성능을 보임.

모델 효율성 비교

STLM은 최소 파라미터, 낮은 GPU 메모리 사용량, 빠른 속도를 보유하며 실제 응용에 적합함.
4.5. 정성적 평가
MVTec 및 VisA 시각화


- STLM은 결함 영역을 정확히 분리하고, 미세한 이상도 놓치지 않음
- 다양한 객체에서 높은 일반화 성능 확인됨
실패 사례 분석

- 일부 transistor 및 grid 클래스에서 오탐 발생
- 이는 FA 모듈의 민감도 또는 불확실한 ground truth에서 기인
4.7. Ablation Study
| Plain student 제거 | PRO 94.92 → 89.96 |
| Shared decoder 제거 | 효율 저하 및 메모리 증가 |
| FA 모듈 제거 | PRO 94.92 → 91.58 |
| 2-stage 학습 | PRO 94.92 → 90.12 (1-stage가 더 우수) |
| FA 입력 방식 변경 | Concat, Sub 등 시도, 기존 방식이 가장 안정적 |
| Pseudo 이상 확률 변경 | 0.5에서 최적 성능. 1.0일 경우 FNR 증가 (과잉 탐지) |
| KD 제거 | 성능 급감 (I-AUROC 99.05 → 89.40) |
| Logit 기반 distillation | Feature 기반이 더 우수 |
4.8. Discussion and Future Work
- STLM은 다양한 SOTA 방법들에 비해 일관되게 우수한 정확도를 보이며, 특히 모델 크기, 속도, 메모리 사용량 측면에서 강력한 경쟁력을 가짐.
- 실시간 응용, 모바일 디바이스, 로봇 비전 시스템 등 경량 모델이 필요한 환경에 적합.
- 향후에는 multi-class anomaly detection과 encoder 속도 개선을 과제로 제시함.
5. Conclusion
STLM은 단순히 정확한 이상 탐지 모델을 넘어서, 실용성, 확장성, 효율성을 겸비한 구조로 설계되었으며, 특히 SAM의 지식을 경량화하여 실시간 처리까지 가능하게 만든 최초의 구조 중 하나로 평가할 수 있다.
이 논문은 "딥러닝 기반 이상 탐지 모델이 실제 현장에 어떻게 적용될 수 있는가?"에 대한 현실적인 해답을 제시하고 있으며, 향후 다양한 비지도 이상 탐지 및 세그먼테이션 분야에 영향을 줄 수 있는 기반 기술로 작용할 수 있다.
'AIPaperReview > Vision' 카테고리의 다른 글
| ENet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation (0) | 2023.03.18 |
|---|
